How much can a Front-end Developer learn about Machine Learning using only JavaScript?
February 13, 2020

Machine Learning and Artificial Intelligence have been huge buzzwords in the Tech industry for quite some time. Hearing them might make you picture self-driving cars or chat bots in your head and leave you wondering what kind of programming goes into those projects. AI, in particular, has been the stuff of science fiction for so long that it’s hard not to be curious about it now that we’re seeing real-life projects surface in the news.
But what do those terms really mean? A cursory search of any of them will undoubtedly leave you separating science from marketing before you get to any valuable information. I’ve spent the past few months learning and researching Machine Learning and the Data Science field, so I know how difficult it can be to drill through the buzz and hype. This article is about that experience and how far I was able to get as a humble JavaScript developer.
Before we get started though, I want to kick things off with my favorite quote about Machine Learning and AI:
Difference between machine learning and AI:
If it is written in Python, it’s probably machine learning
If it is written in PowerPoint, it’s probably AI
I thought Machine Learning was only for geniuses (and I’m no genius)
I first started working with Machine Learning (ML) early on in my career when working with a team that was doing text-recognition work. My job was to create a front-end application that let users send documents to the backend for parsing.
Python is the main squeeze when it comes to ML/AI work for a lot of reasons, so I thought I wouldn’t get much exposure to any ML work as a front-end developer. However, I ended up tangling with ML quite a bit. Text Recognition models are pretty picky about input, so I ended up using JavaScript implementations of Python libraries to pre-process documents in the browser to match the backend. Through this, I also found JavaScript versions of Machine Learning frameworks as well. Not only could you use trained models to predict data in the browser, but you could create and train models there too.
While it was awesome to see that JavaScript can really do all the things, Machine Learning is a specialized field that has massive foundations in calculus and statistics. So while I felt competent in my JavaScript abilities, I felt incompetent when it comes to the kind of higher level math involved in ML. In short, I thought the whole data science field was beyond me as a lowly front-end developer.
After moving on from that work project, I didn’t touch Machine Learning for months.
You don’t need to be a Mathematician to try your hand at Machine Learning

(Pictured: What I thought all Data Scientists looked like before this journey.)
Even though I gave up on ML, I still wanted to learn Python. I run a meetup, so I decided to get some workshops together to teach the community (and myself) Python. I reached out to the local Python User Group. Its organizer, Michael DuPont, and I got together and planned out a series of talks and workshops where Michael would teach, and I would book the venues.
The workshops were awesome, and we were also able to record them for YouTube. That experience taught me a lot about Python and its ecosystem, but also some interesting lessons about Machine Learning.
At the end of the intro talk, Michael introduced TPOT—an automated ML tool—and used it to train a model to predict housing prices in Boston. This was fascinating to me because what TPOT does is take data and figure out how to make a model and train it on its own. It essentially cut out all the math and statistics for you. This planted the seed in my head that maybe, just maybe, being a developer is enough to get your feet wet with ML.
Using JavaScript for Machine Learning
I also run a podcast, and through that, I ended up meeting Gant Laborde, a JavaScript developer with a passion for data science. We interviewed Gant about Machine Learning in JavaScript, and really dug into how to get started with ML.
Gant also revealed that he was working on a JavaScript Machine Learning course. This piqued my interest because almost all ML tutorials focus exclusively on Python. After we were finished recording, I offered myself up as a guinea pig for Gant’s course, and he graciously sent my co-host and I copies of the course to try out ourselves.
Shortly after, Gant released a free intro to Machine Learning course. Naturally, I signed up for that too.
The main course is meant to take 3 weeks, and the intro course is meant to be a 5-day course.
…It took me about 3 months to work through both courses.
My completion time ballooned past the projected 4 weeks for both courses because of my busy schedule, but also because I truly wanted to grasp the material and give myself every chance to learn everything that Gant had poured into the course.
So I took my time ⏳, drank many cups of coffee ☕, and wrote a lot of code 👨💻.
Let’s talk about what I’ve learned 🧙♂️.
Machine Learning is really about prediction 🔮
The general intro course was a fantastic intro to Machine learning. It taught me that ML is really about boiling a data set down to numbers, analyzing a huge group of those numbers, and then being able to predict outcomes when given data it hasn’t seen before. It also taught me about the types of Machine Learning and their applications in real life.
The Machine Learning and Data Science that we deal with are more about Artificial Narrow Intelligence (ANI) than Artificial General Intelligence (AGN). AGN is the stuff of science fiction: robots that can function like humans and make decisions for themselves, SkyNet, etc. ANI is about focusing on a specific problem or question. Some examples of ANI include figuring out if a picture is of a cat or a dog, predicting sales numbers based on historical data, or detecting when a person’s eyes are open from a video feed.
But how does an algorithm learn to answer those questions?
In the example of the Boston Housing data, the data set has a bunch of features like location, crime rate, proximity to schools, etc. that the computer analyzes alongside the price of the home. An ML algorithm will read thousands of those data points to be able to approximate a home price based on those features.
Think about a line from your middle school math classes. There’s a formula that will tell you what x and y coordinates will fall on that line with 100% accuracy. Let’s say our line has a formula of y = x. Using that formula, we could very easily figure out if a set of coordinates are on that line, right? If you have points (0, 0), (1, 1) and (2, 2), you know that as long as they’re equal, they live on the line.
But how would Machine Learning approach this problem? Imagine you didn’t have a formula that could tell you with 100% accuracy whether a point was on the line or not. How could ML help?
To solve this with ML, you would feed your model thousands of coordinates that are labeled as on or off the specified line. After doing a lot of math and burning a lot of processing time, you’d have a model that could tell you with a certain confidence (a percentage) how likely any given point is to exist on that line.
In a nutshell, Machine Learning is just a computer clumsily learning through trial and error.
This joke tweet really encapsulates the core concept of Machine Learning:
Machine Learning Job Interview:
Me: I’m an expert in machine learning
Interviewer: What’s 9 + 10?
Me: It’s 3.
Interviewer: Not even close. It’s 19.
Me: It’s 16.
Interviewer: Wrong. Its still 19
Me: It’s 18.
Interviewer: No, it’s 19.
Me: It’s 19.
Interviewer: You’re hired.
What kind of coding is involved in Machine Learning?
Thankfully, the inner-workings (calculus and linear algebra 💀) of training a model are abstracted away from us by ML frameworks like TensorFlow. So we don’t have to construct the actual algorithms used to process data and train models.
However, there’s still a level of math that you have to grapple with when dabbling in Machine Learning. You need to first be able to process data to pass into ML algorithms and models. You also need to have some knowledge of ML framework settings and configuration.
Preparing Data
Most of the work done by data scientists is involved in preparing the data. When we interviewed Data Scientist Amelia Bennett on our podcast, she described herself as a high-paid data janitor and described data science itself as a “21st century dirty job”.
If you’ve ever wondered how a computer can learn to parse images, sounds, and language, the answer is math. Anything that can be described mathematically can be translated to numbers and fed into ML models. The job of the data scientist is to not only select the data, but convert it. In computer vision for example, this means converting images to arrays of pixels (RGB and location) that the algorithm can use for training. Natural language processing involves describing soundwaves using math—taking frequency and pitch numbers over time to identify spoken words.
Fortunately, there are tools to help you convert non-number data to numbers out there. Tensorflow has a lot of utilities dedicated to helping you process images for instance. Still, you need to be able to use those tools and know which ones to reach for.
Training Configuration

Machine Learning frameworks abstract away most of the math, but you’re still stuck needing to know how different algorithms affect training. So you won’t be solving any problems on paper, but you’re still going to be reading about mathematical concepts with scary names like softmax, sigmoid, and ReLu.
There’s also something to be said about the amount of terms like those activation function names I mentioned above. When using tensorflow specifically, you might feel like you’ve got more knobs to twist and turn than you really know what to do with. The TensorFlow API is massive, and it’s hard to imagine someone mastering all of it.
Note: You may remember that there are autoML frameworks like TPOT that I mentioned above. These don’t require a ton of configuration, but also give you less control over the outputted result. While these tools are useful, you’ll likely find yourself using something TensorFlow or something similar the further you get into ML.
Guess Work
I personally found the amount of configuration at my fingertips to be completely overwhelming. I am the type of person that loves to know exactly what I’m doing and why. However, this left me at odds with a data scientist’s typical workflow.
Machine Learning requires a lot of experimentation. I used to think that data scientists trained models in one go, but in reality they may train models over and over again before getting desirable results. When training models, there’s many various settings to tweak, and selecting the right ones is more of a matter of trial and error than anything else. I had to let go of my need to understand and comprehend everything before I could embrace the experimentation required to solve ML problems.
To put it another way, data scientists are a bit like fictional mad scientists haphazardly mixing chemicals in a lab—except data scientists are mixing mathematical functions together instead of fluid-filled beakers of various colors.
Examples of Machine Learning with JavaScript
I got a solid foundation in the basics of how Machine Learning works, but what projects have I been able to build with it? Before we get to the code, let’s talk about how to employ ML as a developer.
There’s really two main types of projects when you’re working with Machine Learning: using a pre-trained model, or building and training your own model. I’ve included examples of both below.
Note: These demos were all made from concepts and lessons learned from Gant Laborde’s AI course.
Pre-trained Model Examples:
These are super fun apps to make, and require almost no ML knowledge to pull off. I recommend trying some of these yourself! You can quickly make some impressive ML projects by utilizing browser APIs and web technology.
Image API + MobileNet Example

In this demo, I pulled images from the lorem picsum API and used React to hook them up to MobileNet, which is a pre-trained model that can classify images.
Lorem Picsum is mostly random artsy still-life and landscape photos from Unsplash, so you get some interesting results from MobileNet’s classifications.
Webcam + MobileNet Example
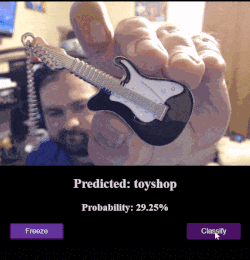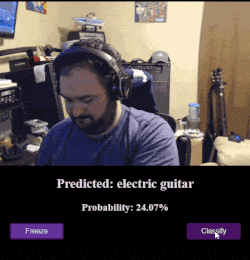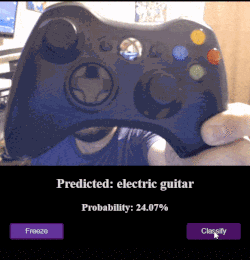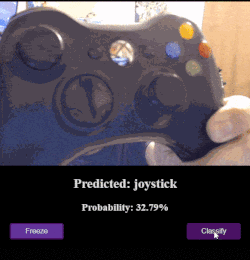
This app connects MobileNet up to the webcam browser API so that you can point your phone/camera at an object and classify it.
(If you’re wondering about some of the crazy results, you should know that MobileNet wasn’t trained recognize humans.)
Browser-based Model Training Examples:
Now we get into the heavy stuff. Beware running these on low-end phones and devices.
These examples take data sets and use them to train models directly in your web browser using JavaScript!
Solving FizzBuzz with TensorFlow
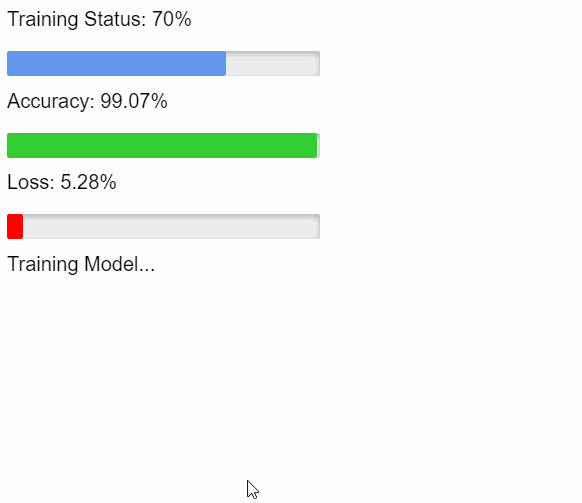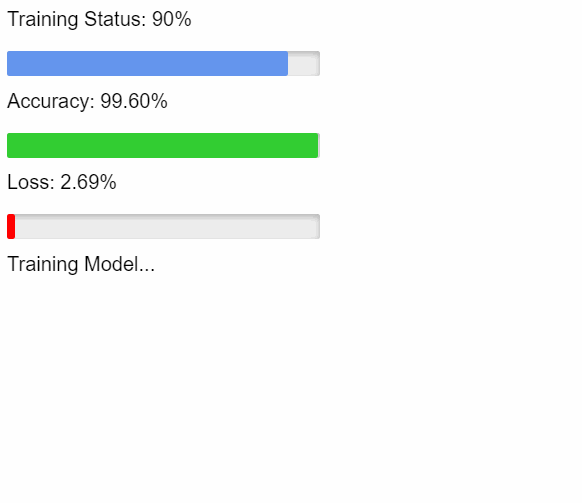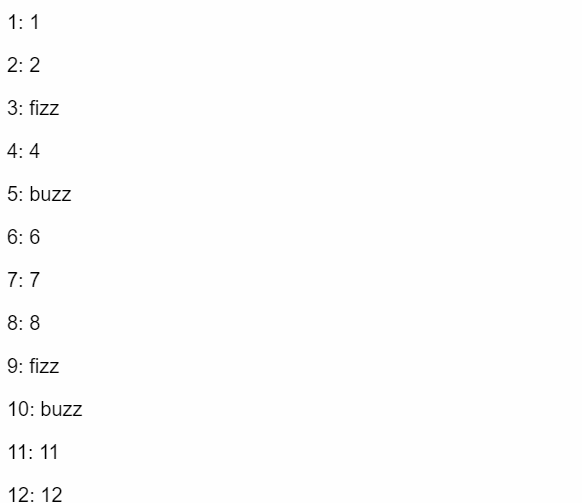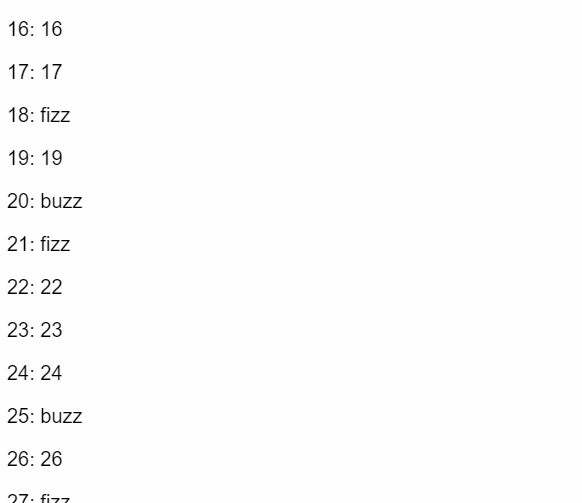
This example feeds a model thousands of numbers (100 through 3100) that have been solved (labeled) using a simple fizzbuzz algorithm. Then it tries to guess whether numbers 1-100 should be fizz, buzz, or fizzbuzz.
Cat/Dog image recognition with TensorFlow

This app uses Gant Laborde’s dogs-n-cats npm package to train a model to recognize random dogs or cats.
Click here to check out the demo on codesandbox. Be warned though, it’s a bit memory/resource intensive to train a model using 2000 images in the browser.
The dogs-n-cats package does most of the prep work for you behind the scenes by pre-processing and pre-packaging all 2000 dog/cat images into tensors for you. All I had to do was feed the images directly into a model for training.
Other Types of Machine Learning
The examples above all involve supervised learning, meaning we are telling the algorithm what to look for and giving it labeled examples to learn from. Supervised learning is fairly simple to wrap your head around, but there’s more methods and applications of ML out there.
Two examples of different ML methods are unsupervised and reinforcement learning. In unsupervised learning, you give the algorithm a data set that’s unlabeled and let it discover and classify things on its own. With reinforcement learning, where the algorithm learns how to accomplish tasks through good or bad outcomes. Think of a computer learning to beat a mario level as an example.
I’d love to dip my toes into these other types of ML at some point, but believe me when I say that getting this far with supervised learning was a huge milestone all on its own!
Are you a Data Scientist now?

Let’s get this out of the way: I am definitely not a data scientist after spending a little time with Machine Learning.
That said, I have learned a lot about what is actually involved in Machine Learning and how Data Scientists have been able to pull off some of the incredible advances we’ve seen in the field. I have a solid understanding of the magic (read: math) that’s behind computer vision, natural language processing, and other miracle technologies.
I also understand the limitations of Machine Learning and know that there’s still quite a lot of work to be done in the field. I’m excited to see what happens as more data sets and better, more accessible ML frameworks become ubiquitous.
As far as training models, I definitely feel like I’m still a novice. There’s so much nuance and intuition involved in selecting proper activation functions, filters, epochs, etc. that I hardly feel qualified to do anything more than guess at how to properly train a model.
I’m also well aware of the massive shortcuts in data preparation I employed. I feel confident that I could train a model from spreadsheet data, but when it comes to preparing and labeling images for training, I still have a long way to go.
Parting Thoughts
Data Science and Machine Learning are really cool things to dip your toes into if you can stomach the mathematics and trial-and-error that’s involved. It’s a challenging area of technology and something that businesses have begun to heavily invest in, so even having a basic understanding of the data science field is invaluable as a developer.
I definitely recommend Gant’s free intro course to ML/AI concepts. If you complete that course and feel like you want to pursue the subject further, I recommend checking out Gant’s paid beginner course on AI/ML in JavaScript as well. Gant worked very hard to make the concepts within approachable and it shows.
I hope to keep advancing my own Machine Learning skills in the future. If you have ideas on where I should go from here, or questions about this post, hit me up on Twitter! I’d love to hear from you.

Written by Lee Warrick, Co-host of the Tech Jr Podcast, Software Engineer, Guitarist, and Gamer. Subscribe to my newsletter! Show your support by buying some SWAG.